
A fun way to test systems, processes and team responses.
What is a GameDay?
A few weeks ago, I was given the opportunity to participate in a GameDay on a client engagement. As this would be my first Gameday, I was super excited, however I had little idea about what to expect, or how I should prepare for it.
I decided to do some research, and found the definition of a GameDay in the AWS Well-Architected Framework documentation:
“A GameDay simulates a failure or event to test systems, processes, and team responses. The purpose is to actually perform the actions the team would perform as if an exceptional event happened.”
Essentially, a GameDay is another way to test your software before it is launched into production. It focuses on putting a system (and the people involved) under stress and testing the practices and solutions to recover it from disasters.
In fact, during my research I also came across some GameDay resources on the DiUS website, including tools and techniques for chaos engineering. You can check them out here.
In this blog post, I’ll share my own personal experience from participating in a GameDay, with a focus on the more technical side of things.
Who should participate in a GameDay?
From the technical team to production support, frontline staff and user experience designers—everyone in the team should be involved in the GameDay to ensure a customer-centric view is taken.
It is also important for everyone to understand their roles during the GameDay, so they can learn how to perform well under pressure should an ‘exceptional’ incident happen.
Why do you need a GameDay?
There are a tonne of benefits from running a GameDay, that are not only for the team, but also for the individual.
Firstly, a GameDay provides the opportunity to gauge the capacity and speed at which the team can solve potential issues, in a measurable way. This can have a range of benefits such as instilling confidence to solve future issues or highlighting the need to focus on solving issues faster, if it is taking longer than expected.
Secondly, by emulating these problems and solving them, it can highlight pain points that are causing the team to solve issues too slowly. This allows you to identify and fix these pain points before they actually impact the team in a real life scenario. Also, it gives you an opportunity to create a playbook which provides information to current and future developers on ways to identify and resolve issues in the future.
Additionally, a GameDay provides an opportunity for lesser skilled members of the team to upskill on harder to gain knowledge such as cloud, pipelines, IAC (Infrastructure As Code) and security.
And last but not least, it brings everyone together and allows the team to socialise in a way that is different from their day-to-day job.
Preparing for a GameDay
There are multiple ways to run a GameDay based on the system and requirements of the team.
To help me prepare before the event, I read up on other organisations who had run GameDays (some examples here) and found they can be organised in several ways, such as within a single team to perform their own strategy on some known / unknown scenarios or by setting up a competition between multiple teams to attack / defend each side.
In our case, we chose the latter because it made more sense for the team to play random attacks, and also it would be more fun to compete against each other.
Before the event, we were split randomly into two teams: Team-A and Team-B. I was in Team-A, along with one other developer. The idea was to compete with each other by attacking the opponent’s team instance, whilst protecting our own. Each team member was able to communicate with their teammates via Zoom to share their attacking strategies and plans before the GameDay.
This is the spinner we used to randomly create the teams
We had three main goals for our GameDay, these were to:
- Maximise the reusability of the attacks we performed for future GameDays.
- Avoid having any effects on other systems or any live demo environments.
- Automate the process as much as we could from attacks to recovery.
To ensure we achieved these goals, our team ran a workshop to explore all the potential attacks that could cause the system to go down.
We then listed and categorised these potential attacks in a Miro board for us to review, and included details such as:
- Where the attack was from and what form it could take.
- How it could affect the system.
- Whether the attack could be automated in script or if it needed to be executed manually from the console or terminal.
This was a great opportunity for the team to get together and brainstorm the risks and disasters the system could face during the GameDay. These potential attacks then got added to our playbook, creating a template for the team to add new attacks and solutions, and help current and future developers on ways to identify and resolve issues in the future.
A Playbook is a guide for the system with instructions and references to help teams fix issues for real customer scenarios in the future.
By doing this, it creates a template for the team to add new attacks and solutions for when the product launches to production or grows further.
Secondly, we created two instances of the system so that both teams could operate concurrently. This step required the infrastructure to spin up multiple isolated instances with access only granted to a certain group of people.
Our system infrastructure was managed by Terraform which has a feature to create multiple workspaces. This allowed the team to attach the namespaces easily to the instance and manage the lifecycle of the infrastructure resources.
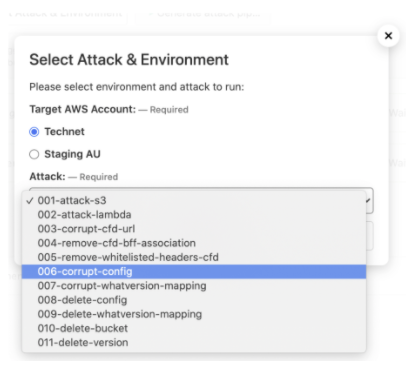
The pipeline on Buildkite to simulate attacks
We also built two separate pipelines to run the attack scripts on demand. Each pipeline allowed the team to run the attack scripts automatically and easily in just a few clicks, and most importantly, generate the logs of each script for the engineers to debug.

Team-A attack pipeline
Permissions were given to certain people to access the pipeline, so Team-A were not able to see which attack scripts Team-B were executing, and vice versa.
Let’s hack together!
Before our GameDay started, the judges announced some rules and conditions. These were:
- Only one active attack per site at any given time.
- A message notifying that the site<X> is down will be posted in the channel.
- Once the issue has been resolved, a notification that the site<X> is back up should be reported in the team’s channel.
- Timekeeper will handle scoring using the timestamps of the above messages.
- Both teams will maintain notes on the fixes and share in their respective private team channels once the issue has been resolved, along with the method used to resolve (manual/auto).
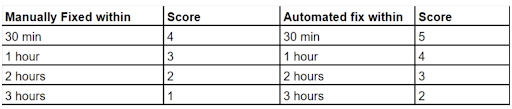
- Scoring is time-based as below.
Our team planned ahead, optimising the task assignment to keep our stress levels low. One of the developers was focused on monitoring the system to make sure we were aware of the attacks, as well as execute the attacks on the opponent’s system. Whilst the other developer was focused on fixing the problems encountered on our system.
Both teams agreed to have some random / surprise attacks that were out of our original scopes and not prepared for prior to the event.
Our team decided to surprise attack the opponent by deleting their API Gateway stage variables. It crashed their system by mismatching the versions between the API Gateway and the backing Lambda function. This kind of attack is difficult to find, but can be solved easily by redeploying the instance.
There was also a surprise attack from our opponent by overriding the API throttling limit which caused the error “TooManyRequestsException” so the user couldn’t access the system’s main page as they normally could. We found this error very quickly from the log, but it took us a very long time to solve. We redeployed twice, but found it wouldn’t fix, so we decided to rebuild the source completely which fixed the error.
Frankly speaking, even though we thought we had prepared well for our opponents attacks, it was still really intense during the GameDay.
The following screenshot shows how ferocious the competition was between the two teams:

Timeline of our GameDay
During a GameDay, it is important that you pay attention to the system logs and fix the issues while taking notes and documenting how you found the problems, as well as how you solved them.
There were some scenarios where users couldn’t access our system and received an error page. The error code was often different, which led us to work out the quickest solution to solve the issues, for example:
- A 500 error could be from the corrupted configuration of the infrastructure.
- A 404 error could be some issues from Cloudfront or DNS settings.
To help us solve these issues, we took the following approach:
- Double checked the issue to see if it was consistent.
- Went through the system / cloudwatch logs and found the error message.
- Verified the errors in the console.
- Solved the problem either through an automated pipeline script or manually.
- Made sure the issue was resolved correctly and the system back up and running as normal.
Surprisingly, when the result of the GameDay was revealed, both teams were feeling happy and rewarded – it was a DRAW! Team-A played more attacks than Team-B, but Team-B launched the attack that took the longest time for Team-A to fix.
Here is a behind the scenes with some memorable moments from our GameDay.
Team conversations during our GameDay
Some final thoughts on our GameDay
During a GameDay, you can’t simulate all types of attacks. In fact, a GameDay should be treated as a regular exercise by the team so that more attacks, bugs and solutions can be documented and added to the playbook. It will make life easier when the product goes live in production and such issues are happening in the future.
We had a retrospective session after the GameDay, and it was agreed within the team that there were a lot of things that could be improved for the next time. For example, some of our attacks and recovery approaches were not automated and some of the attacks we planned didn’t go well or have the expected effect on our opponent.
I found our GameDay super valuable. Not only did it help us to test our system thoroughly, and understand and improve its weaknesses, but it also brought everyone together as a team to solve difficult problems and build our confidence. With lots of sharing and learning, the culture and creativity of the organisation was well-reflected.
Overall, we had a lot of fun, which is equally as important as fixing the bugs and problems.
I hope this blog post gives you some ideas of what a GameDay could look like, and how you can host your own.




