
As you may or may not know, DiUS recently released its Machine Learning in Australia National Pulse Report, which provides a deep dive into the latest ML trends. I’ve been interested in this space from a practitioner perspective for a long time, so to get a broader perspective of how organisations are adopting ML is great, especially as there’s not much Australia-specific data out there.
In this article, I wanted to add some ideas on how the report can be useful for engineers interested in ML upskilling. For someone who gets excited about news of amusing AI experiments and examples of ML going into production, this report is worth a read to help me target my learning goals.
82% of organisations are interested in ML, but only 21% have a project in production.
Having just that quote from the survey already made me think of two things. First, I know that some organisations are interested in ML, but I did not expect it to be 8 out of 10 — which is a good thing. There is a bigger than expected community to start those ML conversations and possibly learn from each other’s ML journey. Second, “only 21% have a project in production” shows an opportunity not just for the organisations but also for developers and engineers to upskill and help transition those ML interests into ML adoption.
Upskilling by “learning machine learning” is something that should be on every engineer’s to-do list. As the DiUS report reveals, there’s a strong appetite for ML in the Australian market, its adoption is only going to accelerate, and businesses know it can deliver value. From an engineer’s perspective, it could also mean more interesting work and increase the impact you have on a daily basis.
However, it would be better if that upskilling is targeted. It’s not just being lazy here but I prefer to describe it as prioritising, following the lean principles and making the best use of what we have. In addition, I think the Australian ML report can provide some guidance and I highlighted some of these in the next sections.
Okay, so maybe before those highlights, one more stat wouldn’t hurt. Most organisations (82%) have some ML capability; however, only 39% have what they consider to be sufficient. And this skills gap exists even with the early ML adopters. Another stat telling us about the opportunity to upskill.

Figuring out where to start
The report also mentioned that ML interest is across multiple business areas, so upskilling doesn’t necessarily mean a drastic job change for an engineer like becoming a data scientist, as there are actually many different roles involved with ML projects. A possible starting point may be knowing the company’s current status in the ML journey. Is the company starting, considering, experimenting or applying? Determining the company’s ML journey and what might be needed for it to progress is probably a skill in itself. But as you get closer to knowing your company’s ML journey, aligning your growth to the current ML journey will help prioritise which skills are needed.
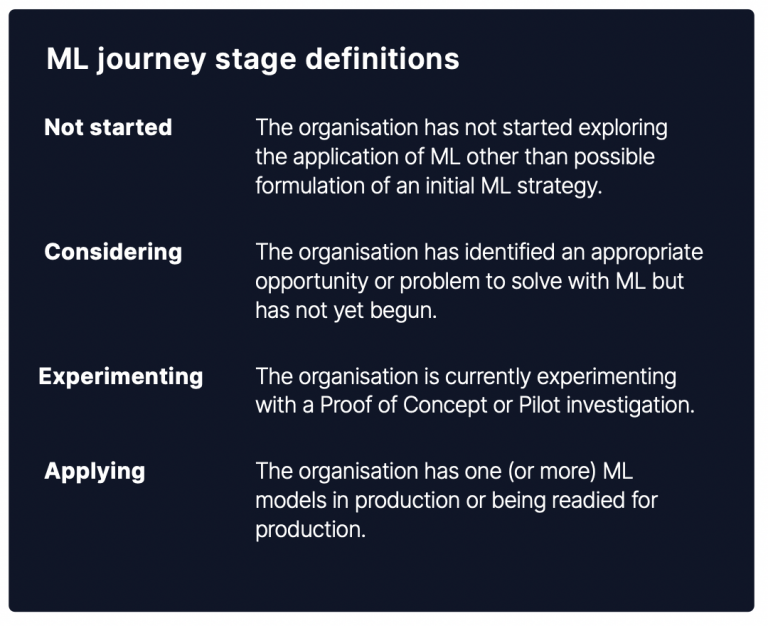
For example, if the organisation has not started in their ML journey, a focus can be placed on initially upskilling with offered ML services from current vendor cloud providers like AWS, GCP or Azure instead of prioritising on learning a custom ML model. There are opportunities that could use ML as a service such as Amazon Rekognition, Personalize and CX Cognitive Suite.
Upskilling to handle data challenges can also be influenced by the ML journey stage. Some organisations may not even have a data platform yet and may be more involved in data collection and cleaning.
Learning when and when not to use ML
Just going back to the quote that only 21% of ML projects make it to production, I think an important part of upskilling is to learn when and when not to use ML for business problems that may contribute value. This will probably take a lot of practice and there will be times we may not always get it right. For most ML materials, thinking both when and when not to use adds more value to the learning. Projects that have gone through this thinking will have a better chance of moving those ML ideas into production.
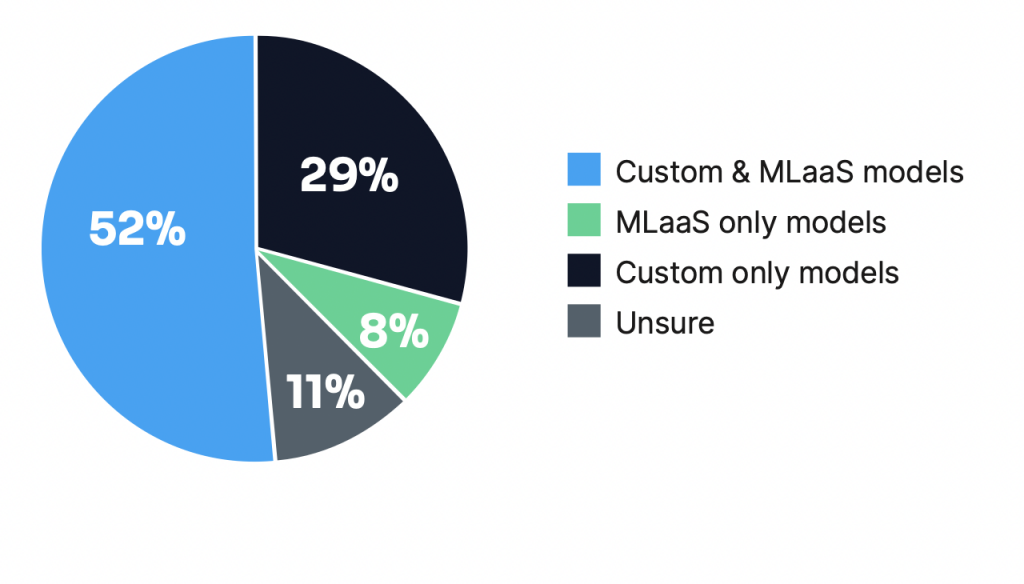
Just because ML is cool or just to show that you can do it does not mean that the problem should be solved with ML. Do we have suitable data? If narrowed down that ML might be the best option, you’ll have to choose what kind of ML and implementation. There are also constraints that we may need to be aware of. If explainability is important to the business or users, we may need to consider techniques other than deep learning. In terms of implementation, we might ask if it could be done through ML-as-a-Service, custom models or a combination of both? Does it make sense to start with ML-as-a-Service to set a benchmark and some early learnings? The survey did show the commercial application has varied combinations when they are in the later stages of their ML journey.
Engineering data
Once the ML journey is started, the survey highlighted that data-related problems are prevalent in the rest of the stages – data-related challenges placed in the top two challenges to ML adoption in the report’s findings. And although there is no single reason for the data challenges (see below), some of the improvements that can be made on data handling and security.

If your ML project is lacking relevant data, there are multiple ways to get around this.
For missing data, a suitable imputation technique instead of automatically dropping rows can help improve the model accuracy. Knowing the pros and cons of techniques like mean imputation, k-nearest neighbour, multivariate equation using chained equations or even using neural networks will come in handy. There are also ML services that do not require a large training dataset for an acceptable accuracy such as those using few-shot learning. Even simple data augmentation techniques can increase a limited training dataset. If we want to identify a beagle in a photo, an image transformation such as resizing, cropping, flipping or rotation of those beagle photos can increase the sample size and can help make the model more robust to images taken at different angles. Lastly, collaboration with other roles with domain knowledge can help identify additional features and enrich the current data. Instead of just having just the plain time series feature in predicting airplane seat reservations, additional features from that time series can help the model learn faster. Based on the domain knowledge, there may be more reservations on a weekend or summer vacation. Dates falling on weekends or summer vacation can then be added as features.
And then, there is an aspect of too much data or features that it takes time to process and fine-tune the model, or that there are too many or not so relevant features for achieving an outcome at a specified accuracy. Going through some of the basics of feature engineering may help such as discretisation. Discretisation would involve partitioning continuous features like body weights in pounds into discrete features like grouping the weights to lightweight and heavyweight. Feature scaling can help speed up the machine learning process (although some ML algorithms like tree-based algorithms are insensitive to this).
Another often overlooked aspect in machine learning is security. And yet, data security is one of the key data challenges whether that’s for data privacy or regulatory requirements. Being aware of best practices to improve security with ML workflows can also be useful in forming your security measures. I think designing with security in mind from the start of the project will help resolve challenges in data later in the project. We already have well-accepted practices such as having isolated compute and network environments, giving the least privilege control on ML artefacts, and performing logging. There are also specific ML vulnerabilities that we should also address such as data poisoning where models are trained with tampered data leading to inaccurate prediction and model inversion where features are reverse engineered with adversarial samples.
Tinkering with ML projects
This is probably just an add-on but why not spice up some of your hobbies with some ML projects? For example, what about adding miniature AI race cars to your hobby and learning to deploy ML on the edge? Or maybe AI in visual and media computing would interest you? It needn’t be formal upskilling, but it will enable you to add to your team’s internal capability.
A fun little experiment: reconstructing Japanese woodblock prints as 3D point clouds with machine learning (MiDaSv2) @runwayml @1null1 #runwayml #touchdesigner #ai #pointcloud pic.twitter.com/XnrLLhV8Iz
— Adam Varga (@dmvrg) June 26, 2021
There are available datasets that you can play around with while learning ML concepts. Some of the popular ones include the MNIST handwritten dataset, the Iris flower dataset, or the Titanic dataset. And if you’re up for some challenges with an ML project, invite your friends and join competitions in Kaggle.
Improving your soft skills too
Upskilling as an engineer based on the report also means looking at soft skills too. The report mentioned the importance of showcasing and working with cross-functional teams. Showcasing may improve visibility and the comments taken from the showcasing iterations can also provide feedback. For cross-functional teams, developing those communication and teamwork skills can come in handy. Communication includes demystifying ML and learning how to demonstrate and explain the project with non-technical folks and stakeholders. Engineers working in cross-functional teams with ML should expect to collaborate with many roles such as data, cloud and software engineers. And the team goes beyond engineers as business and experience design roles are also involved. It does not mean we have to build all the practices from the ground up though, as there are already existing engineering practices such as testability, deployability and maintainability that we can apply for ML projects to make sure that it goes and stays in production.
Parting notes
The report gave a reassuring note on the growing interest in ML in Australia and that there are opportunities for engineers to upskill and contribute to moving those ML ideas into production.
If you’re still wondering how to focus your upskilling, knowing the ML journey stage of your company may help. Is the company in the starting, considering, experimenting or applying stage? It is also knowing that not all business problems are best solved with ML. Keeping that in mind, learning the pros and cons of different ML models, will help engineers make value-creating decisions that make it easier to move those formed ML ideas into production. Moving and keeping this ML to production also involves developing those soft skills when working in a cross-functional team. And for me, part of that upskilling is to also have fun with your own projects whether they start with classifying handwritten digits or going deeper into predicting the optimal charging of batteries in swapping stations.
Have a go and think about the ML projects that interest you, and hopefully this is the start of your adventure as part of the ML community.





